Python機械学習プログラミング PyTorch&scikit-learn編

4,620円(本体 4,200円+税10%)
- 品種名
- 書籍
- 発売日
- 2022/12/15
- ページ数
- 712
- サイズ
- B5変形判
- 著者
- Sebastian Raschka 著/Yuxi (Hayden) Liu 著/Vahid Mirjalili 著/株式会社クイープ 訳/福島真太朗 監修
- ISBN
- 9784295015581
理論からPyTorchの各手法までカバー!
第3版まで続くロングセラーのPyTorch版! 機械学習の基本から、PyTorchによる先進的手法まで本格解説―本書の前半は、定番の機械学習ライブラリscikit-learnによる手法を解説。基本的なモデルから単層ニューラルネットまで実装するほか、データ前処理、次元削減、ハイパーパラメーター、アンサンブル学習、回帰分析などを取り上げます。後半はPyTorchの仕組みを説明し、CNN/RNN/Transformerなどの実装を解説。GAN、グラフニューラルネットワーク、強化学習もカバー。基本の理論からPyTorchの実践まで包括的に学べる一冊です。
- 電子版を買う
-
「読者アンケートに答える」「読者プレゼントに応募」の場合もこちらをご利用ください。
書籍の内容に関するお問い合わせはこちら。お答えできるのは本書に記載の内容に関することに限ります。
学校・法人一括購入に関するお問い合わせはこちらへ。
詳細





著者紹介
◆著者
◎Dr. Sebastian Raschka
ウィスコンシン州立大学マディソン校の統計学助教授。機械学習と深層学習の研究に注力している。
オープンソースの熱心な貢献者でもあり、Grid.aiにおいてAI教育のリードとして、人工知能に興味を持つ人々を支援するという、新しい役割を担う予定。
◎Yuxi (Hayden) Liu
グーグルの機械学習ソフトウェアエンジニア。世界最大の検索エンジンの広告最適化のための機械学習モデル/システムの開発・改良に取り組んでいる。
これまでも、さまざまなデータ駆動型ドメインの業務に機械学習サイエンティストとして従事。
◎Dr. Vahid Mirjalili
コンピュータビジョンのアプリケーションに特化したディープラーニングの研究者。
ミシガン州立大学にて機械工学とコンピュータサイエンスの両方で博士号を取得。
博士課程では、実世界の問題を解決するコンピュータビジョンの新しいアルゴリズムを開発し、引用の多い研究論文をいくつか発表。
◆翻訳者
◎株式会社クイープ
1995年、米国サンフランシスコに設立。コンピュータシステムの開発、ローカライズ、コンサルティングを手がけている。2001年に日本法人を設立。主な訳書に、『プログラマーなら知っておきたい40のアルゴリズム 定番・最新系をPythonで実践!』『[第3版]Python機械学習プログラミング 達人データサイエンティストによる理論と実践』『Amazon Web Servicesインフラサービス活用大全 システム構築/自動化、データストア、高信頼化』などがある(いずれもインプレス発行)。www.quipu.co.jp
◆監訳者
◎福島 真太朗
現在、企業で機械学習、データマイニングの研究開発、技術開発の業務に従事。
東京大学理学部物理学科卒業。東京大学大学院新領域創成科学研究科 複雑理工学専攻 修士課程修了。東京大学大学院情報理工学系研究科 数理情報学専攻 博士課程修了。博士(情報理工学)。専攻は機械学習・データマイニング・非線形力学系。
目次
第1章 「データから学習する能力」をコンピュータに与える
第2章 分類問題―単純な機械学習アルゴリズムの訓練
第3章 分類問題―機械学習ライブラリscikit-learnの活用
第4章 データ前処理―よりよい訓練データセットの構築
第5章 次元削減でデータを圧縮する
第6章 モデルの評価とハイパーパラメータのチューニングのベストプラクティス
第7章 アンサンブル学習―異なるモデルの組み合わせ
第8章 機械学習の適用―感情分析
第9章 回帰分析―連続値をとる目的変数の予測
第10章 クラスタ分析―ラベルなしデータの分析
第11章 多層人工ニューラルネットワークを一から実装する
第12章 ニューラルネットワークの訓練をPyTorchで並列化する
第13章 PyTorchのメカニズム
第14章 画像の分類―ディープ畳み込みニューラルネットワーク
第15章 系列データのモデル化―リカレントニューラルネットワーク
第16章 Transformer―Attentionメカニズムによる自然言語処理の改善
第17章 新しいデータの合成―敵対的生成ネットワーク
第18章 グラフニューラルネットワーク―グラフ構造データでの依存性の捕捉
第19章 複雑な環境での意思決定―強化学習
関連書籍




ダウンロード
本製品の読者さまを対象としたダウンロード情報はありません。
お詫びと訂正
誤記のためにご迷惑をおかけし、誠に申し訳ございません。
- 0ページ 口絵のvページ。ページ上の画像(P.92の画像)
- [誤]
※下記のように訂正します。 - [正]
-

- 【 第2刷にて修正 】
- [誤]
- 38ページ 網掛け部分。重みの偏微分の式。4行目の後半部分
- [誤]
※以下のように訂正します。 - [正]
-

- 【 第2刷にて修正 】
- [誤]
- 38ページ 網掛け部分。バイアスの偏微分の式。1行目
- [誤]
※以下のように訂正します。 - [正]
-

- 【 第2刷にて修正 】
- [誤]
- 62ページ 式3.3.9の右辺
- [誤]
※以下のように訂正します。 - [正]
-

- 【 第2刷にて修正 】
- [誤]
- 66ページ コードの下から15-16行目
- [誤]
loss = (-y.dot(np.log(output)) -
((1 - y).dot(np.log(1 - output))) / X.shape[0] - [正]
loss = (-y.dot(np.log(output)) -
(1 - y).dot(np.log(1 - output))) / X.shape[0] - 【 第2刷にて修正 】
- [誤]
- 66ページ コード内コメントの3行目
- [誤]
各エポックでのMSE損失関数の値 - [正]
各エポックでのログ損失関数の値 - 【 第2刷にて修正 】
- [誤]
- 91ページ ページ下の罫枠内コード2行目
- [誤]
feature_names = ['Sepal length', 'Sepal width', 'Petal length', 'Petal width'] - [正]
feature_names = ['Petal length', 'Petal width'] - 【 第2刷にて修正 】
- [誤]
- 92ページ 図3-23
- [誤]
※下記のように変更(口絵vページも同様に変更) - [正]
-

- 【 第2刷にて修正 】
- [誤]
- 136ページ ページ冒頭部分の箇条書きの数字
- [誤]
8.から11. - [正]
1.から4.に変更 - 【 第2刷にて修正 】
- [誤]
- 139ページ 5.1.4項の箇条書きの数字
- [誤]
12.から14. - [正]
5.から7.に変更 - 【 第2刷にて修正 】
- [誤]
- 148ページ 5.2.2項の箇条書きの数字
- [誤]
15.から21. - [正]
1.から7.に変更 - 【 第2刷にて修正 】
- [誤]
- 149ページ 式(5.2.2)
- [誤]
右辺の転置記号T - [正]
転置記号Tを削除 - 【 第2刷にて修正 】
- [誤]
- 180ページ 6.4.3項の箇条書きの数字
- [誤]
5.から8. - [正]
1.から4.に変更 - 【 第2刷にて修正 】
- [誤]
- 183ページ 6.5節タイトル直前の本文
- [誤]
入れ子の交差検証でモデルを選択したほうがよいかもしれない。 - [正]
入れ子の交差検証でSVMモデルを選択したほうがよいかもしれない。 - 【 第2刷にて修正 】
- [誤]
- 193ページ 最初の罫囲みコード下の本文
- [誤]
アップサンプリングしたクラス0のサブセットを結合することで、 - [正]
アップサンプリングしたクラス1のサブセットを結合することで、 - 【 第2刷にて修正 】
- [誤]
- 216ページ 本文1行目
- [誤]
深さが3の決定木 - [正]
3ノードの深さの決定木 - 【 第2刷にて修正 】
- [誤]
- 274ページ 式9.5.2の直前の段落。1行目
- [誤]
訓練データセットでのMSEがテストデータセットでのMSEよりも值がよい(誤差が小さい)ことがわかる。 - [正]
訓練データセットでのMSEの値がテストデータセットでのMSEの値よりもよい(誤差が小さい)ことがわかる。 - 【 第2刷にて修正 】
- [誤]
- 274ページ 式9.5.2の直前の段落。4~6行目。この段落の最後の文
- [誤]
MSEの平方根であるRMSE(root mean squared error)を計算してみるという手がある。RMSEは平均絶対誤差(mean absolute error:MAE)とも呼ばれるもので、正しくない予測值が以前ほど強調されなくなる。 - [正]
MSEの平方根であるRMSE(root mean squared error)を計算するという手がある。または、正しくない予測値が以前ほど強調されない平均絶対誤差(mean absolute error:MAE)を計算することもできる。 - 【 第2刷にて修正 】
- [誤]
- 295ページ ページ末尾の本文の最終行
- [誤]
エルボー法は、歪みが最も急速に大き - [正]
エルボー法は、歪みが最も急速に小さ - 【 第5刷にて修正 】
- [誤]
- 320ページ 式(11.1.8)の最初の式の末尾にバイアスユニットを追加
- [誤]
※以下のように訂正します(4刷・2025/4/16出来)。 - [正]
-

- 【 第4刷にて修正 】
- [誤]
- 332ページ 1つ目の罫枠内コード、下から3行目
- [誤]
mse = mse/i - [正]
mse = mse/(i+1) - 【 第2刷にて修正 】
- [誤]
- 338ページ 式11.3.1の直前の一文内
- [誤]
入力画像のクラスラベルとして2を予測する場合、 - [正]
入力画像のクラスラベルとして1を予測する場合、 - 【 第5刷にて修正 】
- [誤]
- 339ページ 図11-10の説明
- [誤]
W^{(h)}:隠れユニット(行)×特徴量(列)
W^{(out)}:出力ユニット(行)×隠れユニット(列) - [正]
W^{(h)}:特徴量(行)×隠れユニット(列)
W^{(out)}:隠れユニット(行)×出力ユニット(列) -
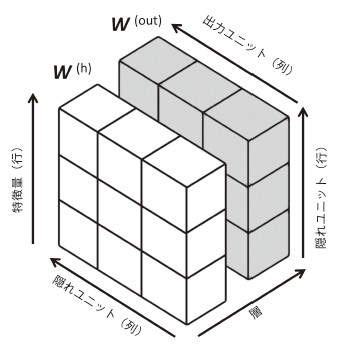
- 【 第5刷にて修正 】
- [誤]
- 342ページ 式11.3.8の右辺。yに下付き添え字1が必要
- [誤]
= 2(a1^(out)-y) - [正]
= 2(a1^(out)-y_1) - 【 第5刷にて修正 】
- [誤]
- 355ページ 最初の罫枠コードの下の本文2行目
- [誤]
テンソルのサイズがchunksの値で割り切れない場合、最後のチャンクは小さくなる。 - [正]
テンソルのサイズがチャンク値で割り切れない場合でも、得られるチャンクの数は常に指定した値になるが、一部(通常は最後)のチャンクのサイズが他よりも小さくなることがある。 - 【 第5刷にて修正 】
- [誤]
- 413ページ コード内の最初のコメント
- [誤]
# Lightning の新しい属性 - [正]
# Lightning の新しい属性
# Torchmetrics 0.8.0 以降では、次のように変更する必要がある:
# self.train_acc = Accuracy(task="multiclass", num_classes=10) - 【 第2刷にて修正 】
- [誤]
- 433ページ 罫枠内コードの12行目以降のforループ
- [誤]
※下記リンクのPDFをご参照ください。 - [正]
ここをクリックしてPDFファイルをご参照ください - 【 第5刷にて修正 】
- [誤]
- 483ページ ページ中央少し上の罫枠内コードの6行目について
- [誤]
※ページ下に下記の脚注を追加 - [正]
[訳注]torch 1.9.0+torchtext 0.10.0の組み合わせ以外では、test_dl = DataLoader(list(test_dataset), batch_size=batch_size, ... のように変更する必要があるかもしれない。 - 【 第2刷にて修正 】
- [誤]
- 553ページ ページ下の脚注※8の2文目
- [誤]
※下記のように訂正します。 - [正]
-

- 【 第3刷にて修正 】
- [誤]
- 554ページ 式(17.1.5)
- [誤]
※下記のように訂正します。 - [正]
-

- 【 第3刷にて修正 】
- [誤]
お問い合わせ
書籍の内容に関するお問い合わせはこちら。お答えできるのは本書に記載の内容に関することに限ります。






